
Il meta tag description
Questo tag è importante perché la sua definizione potrà comparire tra i risultati prodotti dai motori di ricerca (SERP) per una specifica keyword. La sua principale funzione è quella di fornire una breve descrizione della pagina. Dobbiamo però precisare che in alcuni casi i motori di ricerca nei loro risultati SERP potrebbero ignorare questo tag e utilizzare dei contenuti interni della pagina web. È comunque vero che questo tag è fondamentale per dare una descrizione dei contenuti che l’utente si aspetta di trovare visitando la pagina. È perciò consigliabile includere in esso le frasi più rilevanti e le keyword scelte, cercando di dare più importanza alla loro sequenza piuttosto che alla loro ripetibilità.
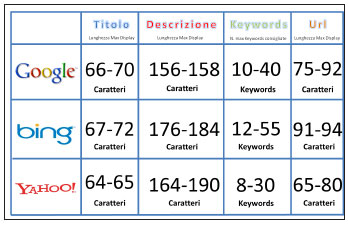
Il meta tag description deve essere uno per ogni pagina e non deve superare le 12-15 parole (massimo 140/160 caratteri). Dunque offre non soltanto la possibilità di rafforzare le keyword (per l’utente) e di individuare o confermare il topic della pagina (per il motore), ma anche quella di presentare un claim attraente per una prima visualizzazione, una sorta di invito all’ingresso. Qui sotto proponiamo un esempio di meta tag description:
<meta name="description" content="Ingegneri del web è un'associazione di ingegneri specializzati nell'analisi, progettazione e sviluppo di applicativi web e software aziendali.">
Nota
I motori di ricerca, per visualizzare i risultati nella SERP, utilizzano porzioni di contenuti prelevati dalle pagine chiamati snippet. Tale generazione avviene in modo automatico e il tag description è utile per suggerire ai motori di ricerca quali informazioni inserire nello snippet. Quindi, anche se è vero che è ad arbitrio del motore di ricerca popolare lo snippet (Google non sceglie solo la description, ma anche una porzione di testo, se ritenuta rilevante), utilizzando opportunamente il tag descripition, potremo influenzare in modo positivo i motori di ricerca e allo stesso tempo migliorare il nostro ranking.
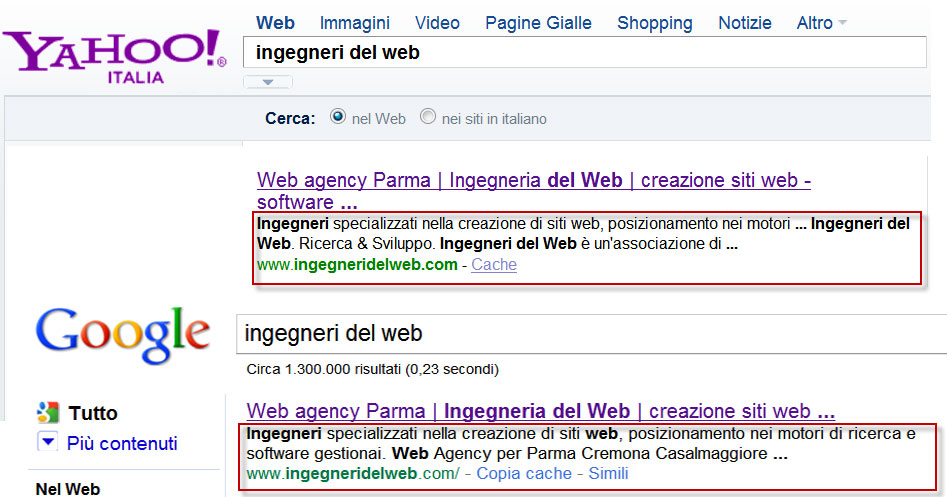
Tra le altre caratteristiche che deve avere il tag description possiamo menzionare queste:
- Deve essere unico per ogni pagina: questo aiuta gli utenti e i motori di ricerca. In caso di CMS o pagine dinamiche è possibile generare automaticamente questo tag prendendolo da parte del corpo della pagina. Per verificare la corretta impostazione dei tag description delle nostre pagine web possiamo utilizzare lo strumento per webmaster messo a disposizione da Google.
- Deve essere coerente con il contenuto della pagina: ovviamente questo tag è una sorta di preview di quello che l’utente troverà visitando la pagina, quindi deve rispecchiare e riassumere il tema della pagina web.
- Deve utilizzare frasi di senso compiuto e non essere generico: è inutile scrivere nel tag description “questa è una pagina” o “questa è la Home Page”. Gli utenti e i motori di ricerca non trarranno nessun beneficio da queste informazioni. Una descrizione del tipo “la società Pinco Pallino produce stufe a legna di qualità, dal design innovativo; vienici a scoprire…” ha sicuramente più valore e conferisce informazioni aggiuntive sulla pagina in questione.
Nota
Per evitare che i motori di ricerca recuperino da Open Directory (DMOZ) le descrizioni da utilizzare nello snippet prodotto dalla SERP, è possibile utilizzare opportuni meta tag:
Per Google: <meta name="googlebot" content="noodp" />
Per Bing: <meta name="msnbot" content="noodp" />
Per Yahoo! <meta name="slurp" content="NOYDIR" />
Il meta tag keyword
Questo tag era usato agli albori di Internet per il posizionamento delle pagine web. A oggi ormai è sorpassato ed è quasi del tutto ignorato dai motori di ricerca. A sostegno di quanto affermato (cioè che il meta tag keyword sia ininfluente per il posizionamento nei vari motori di ricerca e in particolare su Google), troviamo anche la dichiarazione di Matt Cutts, che chiaramente ha detto che “Google does not use the keyword meta tag in web ranking”. Possiamo quindi domandarci se Google abbia mai utilizzato il meta tag keyword ai fini del ranking. Fino a oggi pare di no; è altresì vero come Google sia in grado di utilizzare la Search Appliance per organizzare e filtrare le ricerche in base ai meta tag (incluso il meta tag keyword). Ma questa tecnologia lavora a livello enterprise, quindi per le normali ricerche per il web non viene preso in considerazione il meta tag keyword, che non risulta avere alcun effetto a livello di ranking (almeno per Google).
Il nostro consiglio è quello di utilizzarlo comunque, soprattutto perché alcuni “propagatori di notizie” e directory potrebbero ancora utilizzare tale meta tag (vari motori di ricerca come Yandex, Baidu e altri adoperano ancora il tag keyword all’interno dei loro algoritmi di ricerca). È necessario non utilizzare più di 40 keyword all’interno di questo tag senza ripeterle, separarle da una virgola e interporre tra di esse uno spazio.
Ovviamente le keyword, per essere rilevanti, dovranno comparire anche nei tag title, nella description e nel corpo della pagina. Sotto riportiamo un esempio di utilizzo del tag keyword:
<meta name="keywords" content="realizzazione siti web, posizionamento nei motori di ricerca, progettazione siti internet, indicizzazione nei motori di ricerca, restyling siti web, creazione software, sviluppo gestionali per negozi." />
Quindi possiamo affermare con certezza che questo meta tag è comparativamente meno importante rispetto ad altri. Gli specialisti SEO cercano di aggiungere alcune informazioni nel meta tag keyword per rendere il sito più amichevole agli occhi di un motore di ricerca (e anche dei clienti che commissionano una Campagna SEO), ma la maggior parte dei crawler non considera minimamente questa porzione di codice. Lo scopo del meta tag keyword è quello di rafforzare “l’informazione” trovata all’interno della pagina e quindi migliorarne la reperibilità nel mondo web. Infatti, supponiamo di ricercare in Google una parola che non ha “corrispondenze”: inserendo quella specifica parola come keyword, potremmo sperare di aumentare la popolarità della nostra pagina. Ovviamente, se la keyword non trova corrispondenza nel “contenuto” della pagina, allora sarà molto meno probabile che tale pagina venga indicizzata in modo ottimale. Un altro esempio: se abbiamo una pagina che parla di “equitazione”, è consigliabile inserire come keyword e come contenuto della pagina la parola “cavallo”… ma perché? Perché vi renderete conto che alcune persone possono inserire la keyword “cavallo” al posto di “equitazione”, che sono due parole separate. Se nella nostra pagina queste due parole sono elencate separatamente nel tag delle keyword (e ovviamente anche ripetute nel tag description e nel corpo della pagina), sarà una piccola ottimizzazione utile per aumentare il rank complessivo della pagina.
Nota
A questo link potete visionare i principali meta tag utilizzati da Google.
Il meta tag language
È utilizzato per indicare la lingua della pagina web e sfruttato dagli strumenti di traduzione automatica, come Google Translate:
<meta http-equiv="content-language" content="en">
Su questa pagina potete trovare l’elenco dei codici ISO da utilizzare nel campo content.
Nota
Possiamo specificare che una determinata pagina del sito web non venga tradotta automaticamente da Google impostando il meta tag <meta name=”googlebot” content=”notranslate”>. Se vogliamo che non venga tradotta solo una porzione del codice, è sufficiente impostare l’uso della classe “notranslate” in questo modo:
<div class="notranslate"> testo non traducibile</div>
In alcuni contesti sarà preferibile utilizzare il namespace W3C dell’XHTML (o usarli entrambi) per specificare la lingua delle pagine, come mostra il seguente listato:
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="it" lang="it" dir="ltr" >
Google afferma: “We do not use locational meta tag (like “geoposition” or “distribution”) or HTML attributes for geotargeting”, quindi viene dichiarato ufficialmente come Google non consideri questi meta tag per la localizzazione. Ciò non significa che non dobbiamo usarli: è vero che Google è il motore di ricerca più utilizzato, ma non dobbiamo basarci solo su di esso. Il meta tag in questione potrebbe essere utilizzato da altri motori di ricerca (come per esempio Bing).
Nota
Quando creiamo una pagina HTML, dobbiamo specificare anche il DocType. Il DocType deve essere il primo elemento ad aprire il documento e si tratta di un tag che ha il compito di fornire informazioni al Server Web che ospita la pagina. Le informazioni conferite da DocType riguardano il tipo di doc.mento visualizzato, oltre a essere necessarie alla comunicazione tra browser e server. DocType deve essere scritto in una forma standard, per esempio:<!DOCTYPE HTML PUBLIC “-//W3C//DTD HTML 4.01 Transitional//EN” http://www.w3.org/TR/html4/loose.dtd>.
Su questa pagina trovate un’ottima spiegazione sulla scelta del DocType più opportuno in base alle esigenze.
Il meta tag robots
Questo meta tag ha il compito di indicare al crawler, che scandisce le nostre pagine web, le sezioni a esso accessibili e quelle non indicizzabili, sfruttando il protocollo REP (come per esempio le zone amministrative o le pagine protette). Attualmente, le direttive comuni ai diversi spider sono quattro e hanno i seguenti scopi:
- richiesta di includere (index) i contenuti della pagina nell’archivio del motore di ricerca;
- richiesta di NON includere (noindex) i contenuti della pagina nell’archivio del motore di ricerca;
- richiesta di seguire (follow) tutti i link presenti nella pagina, al fine di individuare altre pagine del sito web in modo automatico;
- specifica di NON seguire (nofollow) tutti i link presenti nella pagina.
Nota
Ci sono diversi modi per impedire che i contenuti appaiano nei risultati di ricerca, come l’aggiunta di “noindex” al meta tag robots, utilizzando .Htaccess per proteggere con password le cartelle, e l’utilizzo di Google Webmaster Tools per rimuovere i contenuti che sono già stati indicizzati. A tal proposito, vi segnaliamo questo interessante intervento da parte di Google.
Sotto è mostrato un esempio di utilizzo del tag in questione:
<meta name="robots" content="index, follow" />
Nota
Se non inseriamo nessun meta robots, gli spider indicizzeranno automaticamente tutte le pagine e seguiranno tutti i link presenti all’interno del nostro sito web. Il meta tag noindex è utile nei casi in cui siano presenti contenuti duplicati, versioni stampabili o situazioni particolari in cui non si vuole che tale pagina venga indicizzata dai motori di ricerca.
È inoltre possibile specificare azioni differenti per gli spider dei motori di ricerca più conosciuti, utilizzando una sintassi del tipo:
<meta name="nome_dello_spider" content="azione_da_compiere" />
Analizziamo i valori non ancora presi in considerazione:
- NOARCHIVE: inibisce la visualizzazione nei risultati della SERP della copia in cache (in memore) per quella specifica pagina;
- NOODP: serve a specificare di non utilizzare la descrizione ODP/DMoz nella visualizzazione dello snippet dei risultati della SERP (come avevamo già accennato in precedenza quando avevamo parlato del meta tag description);
- NOSNIPPET: serve per impedire la visualizzazione dello snippet nei risultati di ricerca dei vari motori;
- NOIMAGEINDEX: è utilizzato per non consentire l’indicizzazione delle immagini presenti all’interno della pagina;
- NOTRANSLATE: abbiamo accennato nel precedente paragrafo a questo tag; inserendolo inibiamo la possibilità di tradurre i nostri contenuti con Google Translate;
- UNAVAILABLE_AFTER ci permette di indicare allo spider la data e l’ora in cui bloccare la scansione della nostra pagina web.
Per informarci che un articolo scadrà in un preciso momento in cui dovrebbe essere rimosso dall’indice di Google, è possibile il seguente tag:
<meta name="googlebot" content="unavailable_after: 25-aug-2010 17:00:00 est">
Un altro esempio che possiamo proporre è quello di dire allo spider di ASK di non indicizzare questa pagina web utilizzando il seguente tag:
<meta name="teoma" content="noindex">
Analogamente, possiamo procedere a crearci i nostri meta tag personalizzati seguendo le indicazioni presenti nella tabella 1. Tipicamente, è preferibile gestire le impostazioni degli spider a livello globale, utilizzando un apposito file di testo chiamato robots.txt riconosciuto dai principali motori di ricerca, ne parleremo nel prossimo articolo.
| Parametro | Bing | |
| Nome Robot | MNSbot | googlebot |
| NOINDEX | Si | Si |
| NOFOLLOW | Si | Si |
| NOARCHIVE | Si | Si |
| NOODP | Si | Si |
| NOYDIR | No | No |
| NOSNIPPET | No | Si |
| NOIMAGE INDEX | No | Si |
| NOTRANSLATE | No | Si |
| UNAVAILABLE _AFTER | No | Si |
Tabella 1: impostazioni consentite dai principali spider
Nota
Una raccomandazione importante circa i contenuti del meta tag robots è quella di non indicare direttive in conflitto tra di loro (per esempio, index e noindex contemporaneamente).